
Pada Senin, 20 Oktober 2025, sebagian besar ekosistem digital global mengalami guncangan serius. Penyebabnya: gangguan besar pada layanan cloud milik Amazon Web Services (AWS). Karena AWS menjadi tulang punggung banyak layanan di internet, ketika satu “zona” bermasalah, efeknya terasa luas — tidak hanya pada properti milik AWS sendiri seperti Amazon atau Alexa, tetapi juga pada ratusan aplikasi dan situs pihak ke-3.
Mari kita kupas secara jurnalis: kronologi, dampak, penyebab sementara, hingga implikasi lebih luas dari kejadian ini.
Kronologi kejadian
-
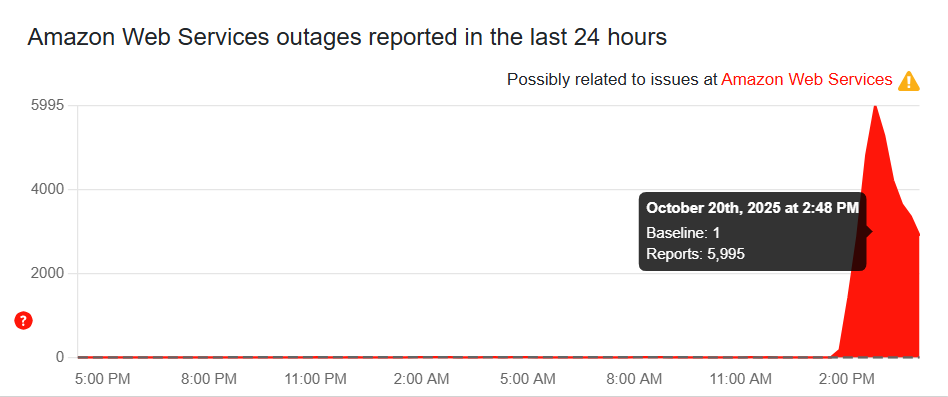
Pukul sekitar 03:11 AM ET (sekitar pukul 15:11 WIB), AWS melaporkan melalui “status dashboard” bahwa terdapat increased error rates and latencies (peningkatan tingkat kesalahan dan keterlambatan) untuk beberapa layanan di wilayah US-EAST-1 (Virginia, AS).
-
Menjelang siang hari waktu Inggris, laporan pengguna meningkat tajam — lebih dari 15.000 pengguna melaporkan masalah dari berbagai wilayah dunia melalui situs pelacak seperti DownDetector.
-
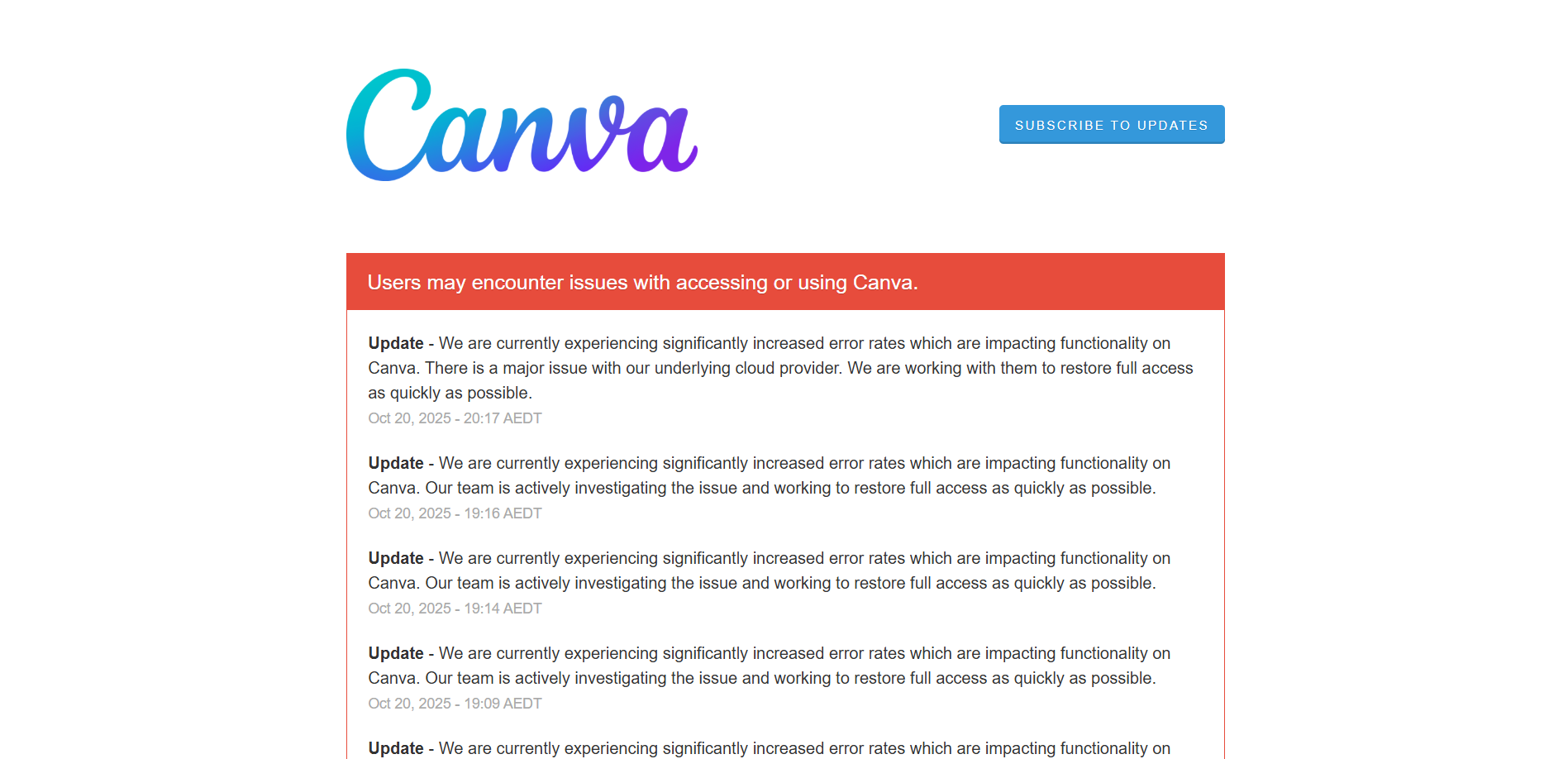
Layanan-layanan besar yang bergantung pada AWS, seperti Snapchat, Fortnite, Canva, dan asisten rumah tangga Alexa, dilaporkan terganggu.
-
AWS menyatakan bahwa tim teknis sedang aktif melakukan mitigasi dan mencari root cause, namun belum memberikan estimasi waktu kapan layanan akan pulih sepenuhnya.
Sebagai catatan tambahan, dalam sejarahnya AWS pernah mengalami sejumlah gangguan signifikan sebelumnya — yang berarti kejadian hari ini bukanlah yang pertama untuk penyedia cloud sebesar itu.
Ruang lingkup dan skala dampak
Gangguan ini dapat digolongkan sebagai “major internet outage” karena beberapa alasan:
-
AWS adalah penyedia infrastruktur cloud terbesar di dunia dalam banyak kategori; banyak layanan besar (baik aplikasi konsumen maupun perusahaan) bergantung padanya.
-
Meski hanya satu wilayah (“Availability Zone” atau “Region” AWS) yang dilaporkan bermasalah (US-EAST-1), akibatnya meluas karena banyak layanan yang tidak memiliki redundansi yang memadai. Ini menunjukkan bahwa “cloud downtime” tidak hanya soal server mati, tetapi soal desain arsitektur layanan oleh klien.
-
Dampak “langsung” meliputi pengguna yang tidak bisa mengakses aplikasi atau fitur yang seharusnya bisa mereka gunakan, serta layanan internal banyak perusahaan yang mendadak lumpuh – seperti sistem autentikasi, basis data, API kunci.
-
Efek “tidak langsung” meliputi reputasi, kepercayaan, bahkan kerugian ekonomi — baik untuk AWS, kliennya, maupun pengguna akhir. Analisis sebelumnya menyebut bahwa bahkan beberapa menit downtime dapat bernilai jutaan dolar bagi bisnis besar.
Contoh spesifik dari laporan:
-
Laporan menyebut lebih dari 35-tools AWS terdampak dalam satu posting awal.
-
Situs besar seperti layanan keuangan di Inggris (Lloyds Bank, Halifax) melaporkan kesulitan karena sistem bergantung ke AWS.
Siapa yang terdampak?
Pengguna individu
Bagi pengguna sehari-hari, gangguan ini terasa ketika:
-
Aplikasi yang biasa dipakai tidak bisa dibuka atau menunjukkan error.
-
Perangkat rumah pintar yang bergantung pada Alexa mendadak tidak merespon.
-
Beberapa game online, platform desain seperti Canva, tidak bisa dipakai.
-
Pengguna di kawasan Asia, Eropa, Amerika semuanya melaporkan masalah — meski penyebab utama di AS.
Perusahaan & Penyedia layanan
-
Banyak startup dan aplikasi yang menyewa layanan AWS sebagai infrastruktur utama mengalami downtime atau fungsi terbatas. Contoh: CEO Perplexity menyebut secara langsung “root cause is an AWS issue”.
-
Perusahaan yang sangat mengandalkan sistem cloud-based, termasuk layanan keuangan, ritel, dan hiburan, terpengaruh — baik langsung maupun lewat vendor pendukung.
-
Beberapa sistem internal perusahaan (backup, logging, autentikasi) yang tak didesain untuk failover penuh menjadi titik lemah.
Ekosistem teknologi global
-
Ketergantungan global pada beberapa cloud-provider besar menimbulkan efek domino ketika salah satu mengalami gangguan besar.
-
Mengingat AWS adalah pemain utama (market share besar), gangguan semacam ini meningkatkan diskusi tentang resilience, multi-cloud strategy, dan redundancy architecture.
Penyebab sementara: Apa yang dikemukakan
Hingga saat ini, AWS belum merilis laporan insiden penuh dengan root cause yang sangat spesifik ke publik (setidaknya hingga artikel ini ditulis). Namun catatan awal mengindikasikan:
-
Zona US-EAST-1 mengalami error dan latensi yang tinggi.
-
Ada indikasi pada subsystem basis data atau API kunci seperti DynamoDB dan layanan terkait. Contohnya dalam liputan: “linked to DNS resolution errors affecting the DynamoDB API, which also impacted related services such as IAM updates and DynamoDB Global Tables.”
-
Seperti banyak gangguan cloud sebelumnya, faktor perangkat keras, perangkat lunak, atau manusia bisa menjadi penyebab – dan kemungkinan besar juga kombinasi dari satu atau lebih zona availability yang mengalami kegagalan dan tidak ada failover otomatis yang memadai. Catatan: “Today’s outage… shows that a lot of people don’t know how to build reliable services… one zone goes down and your services crap out.” Ars Technica
-
AWS telah menyatakan bahwa tim sedang melakukan mitigasi dan investigasi.
Apa yang bisa dipelajari dan implikasi ke depan
1. Pentingnya redundansi & desain yang matang
Peristiwa ini mengingatkan bahwa meskipun layanan cloud sangat handal, ketergantungan tunggal (single point of failure) tetap riskan. Beberapa best-practice yang tercatat:
-
Gunakan multi-region atau multi-zone apabila mission-critical.
-
Uji failover secara berkala.
-
Pantau service-level agreements (SLA) dan transparansi penyedia cloud.
-
Menyadari bahwa “karena layanan cloud besar, berarti tak bisa jatuh” itu mitos — bahwa banyak arsitektur masih terlalu bergantung pada satu zona.
2. Efek reputasi & kepercayaan
Bagi AWS sendiri, gangguan besar seperti ini dapat mengusik persepsi pasar tentang reliabilitas (meskipun AWS tetap besar). Untuk klien yang terdampak, ini bisa berarti: kerugian finansial, kerusakan reputasi, dan tuntutan dari pengguna.
3. Perluasan diskusi “multi-cloud” dan strategi mitigasi
Banyak perusahaan saat ini mengevaluasi apakah hanya satu cloud provider cukup. Insiden ini akan menambah bahan diskusi tentang:
-
Memiliki fallback di provider lain (misalnya Google Cloud, Microsoft Azure).
-
Arsitektur bebas vendor tunggal (vendor lock-in).
-
Menyusun prosedur darurat untuk gangguan besar.
4. Layanan konsumen perlu siap menghadapi gangguan
Bagi pengguna akhir, ini adalah pengingat bahwa:
-
Tidak ada layanan yang 100% bebas gangguan — meskipun bisa sangat jarang.
-
Pentingnya backup atau alternatif jika layanan utama down. Misalnya jika aplikasi desain online tidak bisa digunakan, punya versi offline atau alternatif lokal bisa membantu.
-
Perusahaan penyedia layanan harus memberi transparansi dan respons cepat — pengguna menghargai kejelasan.
Dampak terhadap pengguna di Indonesia & Asia
Walaupun pusat gangguan berada di AS, efeknya terasa secara global — termasuk Asia dan Indonesia. Beberapa implikasi:
-
Pengguna layanan berbasis AWS di Indonesia (misalnya startup lokal yang gunakan AWS) mungkin mendapati gangguan pada produk atau layanan mereka.
-
Bisnis e-commerce/rantai ritel lokal yang mengandalkan platform global atau API dari luar bisa mengalami downtime atau keterlambatan.
-
Pengguna rumahan yang menggunakan perangkat pintar berbasis cloud (misalnya Alexa, smart home) bisa mendapati perangkat tidak berfungsi sementara — meskipun wilayah lokal mungkin belum banyak terdengar dalam laporan publik.
-
Untuk pengguna di Sleman, Yogyakarta, atau kota lain di Indonesia: meskipun gangguan lokal mungkin kecil, tetapi waktu respons bantuan/komunikasi layanan global bisa melambat.
Tinjauan akhirnya
Kejadian ini memberi gambaran nyata betapa “jaringan internet global”—yang terlihat mulus bagi kita sehari-hari—tergantung pada infrastruktur teknis yang sangat kompleks dan rentan terhadap satu titik kegagalan. Salah satu pemain utama (AWS) mengalami gangguan di satu wilayah, dan efeknya menjalar ke banyak layanan dan pengguna.
Sebagai wartawan teknologi, saya mencatat bahwa ini bukan hanya soal “suatu situs tidak bisa diakses” — ini soal ekosistem digital seluruh dunia yang sementara waktu kehilangan sebagian kelancarannya. Untuk bisnis, ini adalah kesempatan untuk introspeksi: apakah sudah memiliki arsitektur yang cukup tahan terhadap gangguan? Untuk pengguna, ini adalah kesempatan untuk lebih sadar bahwa meskipun “cloud” terdengar handal, tetap ada risiko.
Saat ini (tanggal laporan), AWS masih menyelidiki akar masalah dan belum merilis laporan lengkap. Waktu pemulihan penuh masih belum ditentukan publik. Kita perlu terus memantau pembaruan resmi dari AWS dan klien-utama yang terdampak.




💬 Comments (0)
Bergabung dengan 0 orang yang sudah berkomentar. Apa pendapatmu?
Belum ada komentar untuk berita ini.